Spark 3.0 关键新特性回顾
从Spark 3.0官方的Release Notes可以看到,这次大版本的升级主要是集中在性能优化和文档丰富上(如下图),其中46%的优化都集中在Spark SQL上。
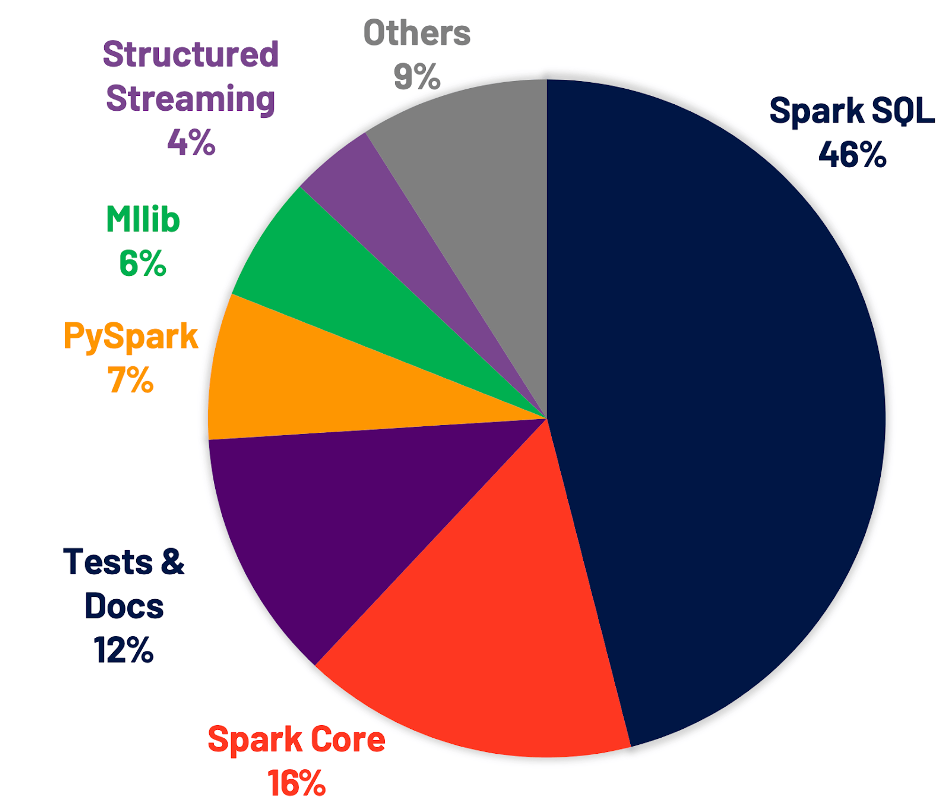
今天Spark SQL的优化不仅仅服务于SQL语言,还服务于机器学习、流计算和DataFrame等计算任务, 因此社区对于Spark SQL的投入非常大。对外公布的TPC-DS性能测试结果相较于Spark 2.4会有2倍的提升。SQL优化里最引人注意的非Adaptive Query Execution莫属了, 还有一些其他的优化比如Dynamic Pruning Partition,通过Aggregator注册UDAF(User Defined Aggregator Function)等等都极大的提升了SQL引擎的性能。
本文会着重回顾AQE新特性及相关关注的特性和文档监控方面的变化。其他更多的信息比如复用子查询优化,SQL Hints,ANSI SQL兼容,SparkR向量化读写,加速器感知GPU调度等等,感兴趣的同学可以参考官网notes。
Adaptive Query Execution (AQE)
AQE对于整体的Spark SQL的执行过程做了相应的调整和优化(如下图),它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。
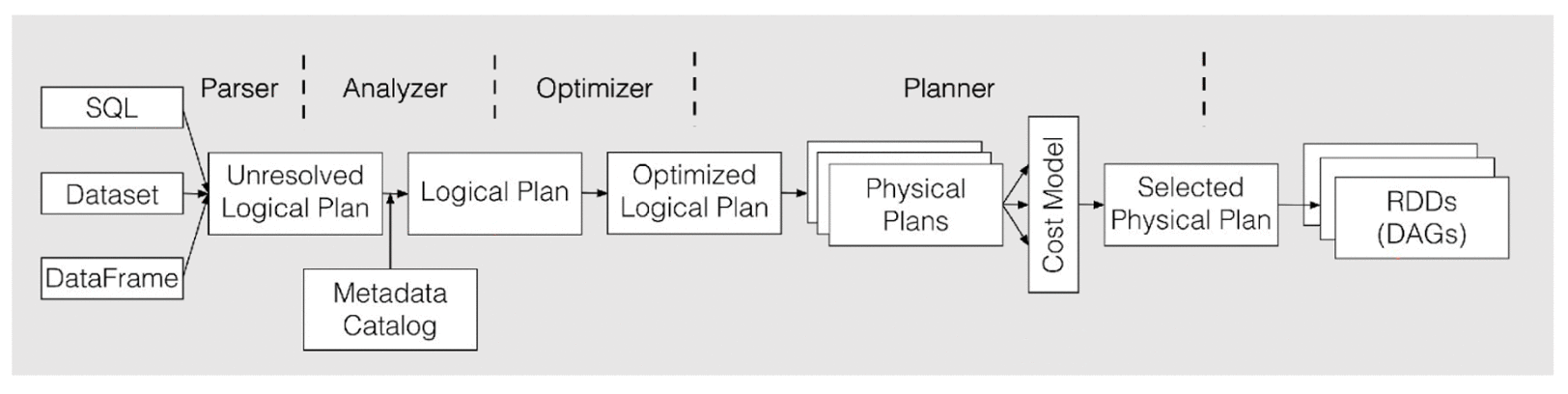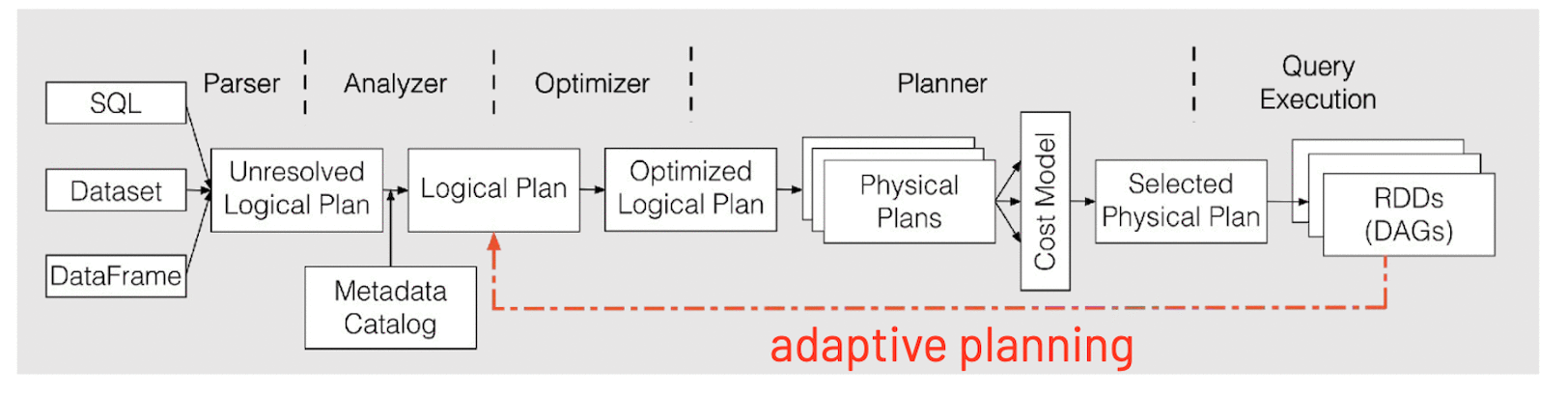 Spark 2.x的SQL执行过程:
Spark 2.x的SQL执行过程:
- 当用户提交了Spark SQL/Dataset/DataFrame时,在逻辑执行计划阶段,Spark SQL的Parser会用ANLTER将其转化为对应的语法树(Unresolved Logic Plan),接着Analyzer会利用catalog里的信息找到表和数据类型及对应的列将其转化为解析后有schema的Logical Plan,然后Optimizer会通过一系列的优化rule进行算子下推(比如filter, 列剪裁),提前计算常量(比如当前时间),replace一些操作符等等来去优化Logical Plan。
- 而在物理计划阶段,Spark Planner会将各种物理计划策略作用于对应的Logical Plan节点上,生成多个物理计划,然后通过CBO选择一个最佳的作为最终的物理算子树(比如选择用Broadcast的算子,而不是SortMerge的Join算子), 最终将算子树的节点转化为Spark底层的RDD,Transformation和Action等,以支持其提交执行。
在Spark 3.0之前, Spark的Catalyst的优化主要是通过基于逻辑计划的rule和物理计划里的CBO,这些优化要么基于数据库里的
静态信息,要么通过预先得到统计信息, 比如数值分布的直方图等来预估并判断应该使用哪种优化策略。这样的优化存在很多问题,比如数据的meta信息不准确或者不全,或者复杂的filter,黑盒的UDFs等导致无法预估准确的数值,因此很难得到较优的优化策略。
主要功能点
此时,提出AQE通过真实且精确的执行统计结果进行优化就很有意义了。基于这个设计和背景,AQE就能够比较方便解决用户在使用Spark中一些头疼的地方。主要体现在以下三个方面:
- 自动调整reducer的数量,减小partition数量
- Spark任务的并行度一直是让用户比较困扰的地方。如果并行度太大的话,会导致task 过多,overhead比较大,整体拉慢任务的运行。而如果并行度太小的,数据分区会比较大,容易出现OOM的问题,并且资源也得不到合理的利用,并行运行任务优势得不到最大的发挥。而且由于Spark Context整个任务的并行度,需要一开始设定好且没法动态修改,这就很容易出现任务刚开始的时候数据量大需要大的并行度,而运行的过程中通过转化过滤可能最终的数据集已经变得很小,最初设定的分区数就显得过大了。AQE能够很好的解决这个问题,在reducer去读取数据时,会根据用户设定的分区数据的大小(
spark.sql.adaptive.advisoryPartitionSizeInBytes)来自动调整和合并(Coalesce)小的partition,自适应地减小partition的数量,以减少资源浪费和overhead,提升任务的性能。参考示例图中可以看到从最开始的shuffle产生50个partitions,最终合并为只有5个parititons: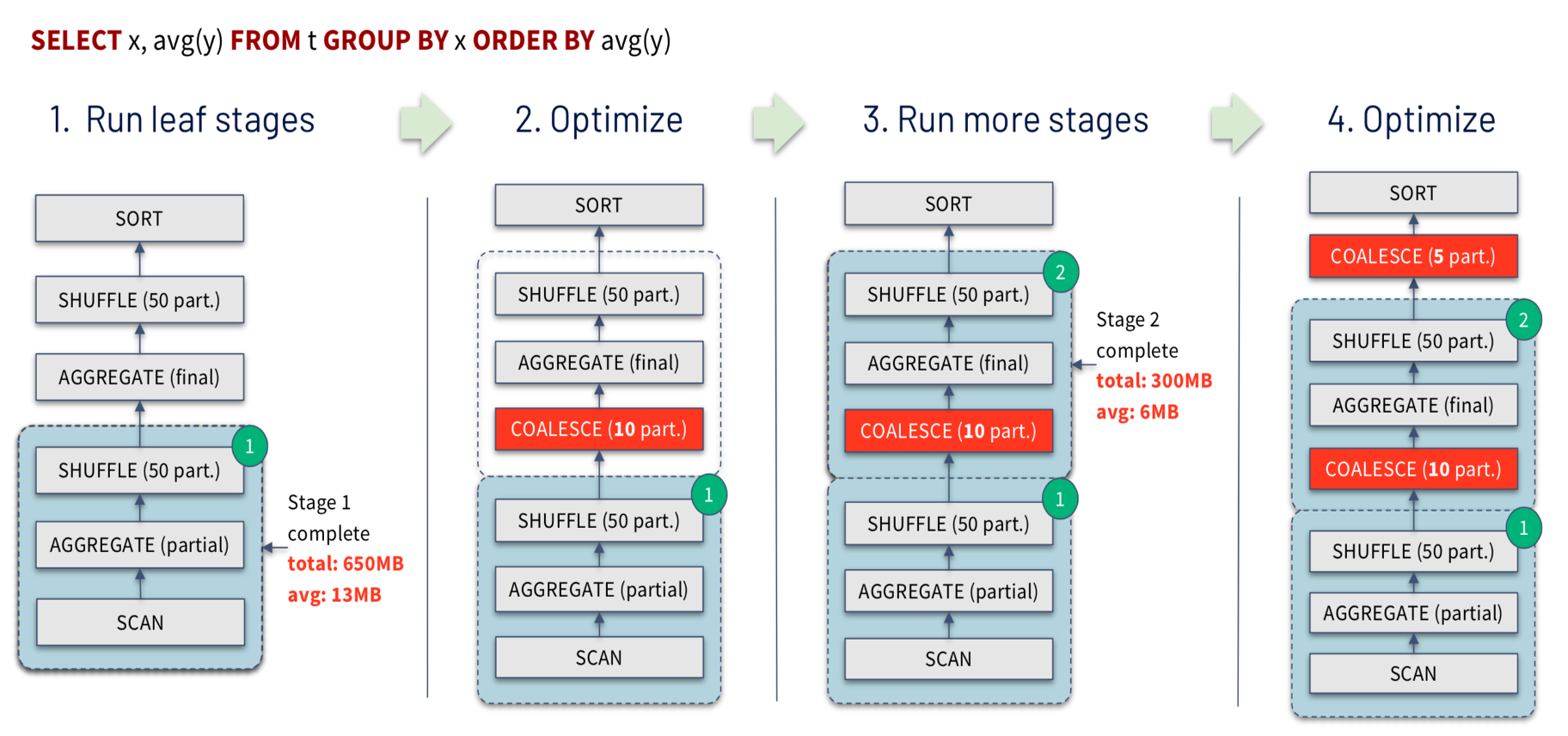
- Spark任务的并行度一直是让用户比较困扰的地方。如果并行度太大的话,会导致task 过多,overhead比较大,整体拉慢任务的运行。而如果并行度太小的,数据分区会比较大,容易出现OOM的问题,并且资源也得不到合理的利用,并行运行任务优势得不到最大的发挥。而且由于Spark Context整个任务的并行度,需要一开始设定好且没法动态修改,这就很容易出现任务刚开始的时候数据量大需要大的并行度,而运行的过程中通过转化过滤可能最终的数据集已经变得很小,最初设定的分区数就显得过大了。AQE能够很好的解决这个问题,在reducer去读取数据时,会根据用户设定的分区数据的大小(
- 自动解决Join时的数据倾斜问题
- Join里如果出现某个key的数据倾斜问题,那么基于上就是这个任务的性能杀手了。在AQE之前,用户没法自动处理Join中遇到的这个棘手问题,需要借助外部手动收集数据统计信息,并做额外的加盐,分批处理数据等相对繁琐的方法来应对数据倾斜问题。而AQE由于可以实时拿到运行时的数据,通过
Skew Shuffle Reader自动调整不同key的数据大小(spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes)来避免数据倾斜,从而提高性能。参考示例图可以看到AQE自动将A表里倾斜的partition进一步划分为3个小的partitions跟B表对应的partition进行join,消除短板倾斜任务: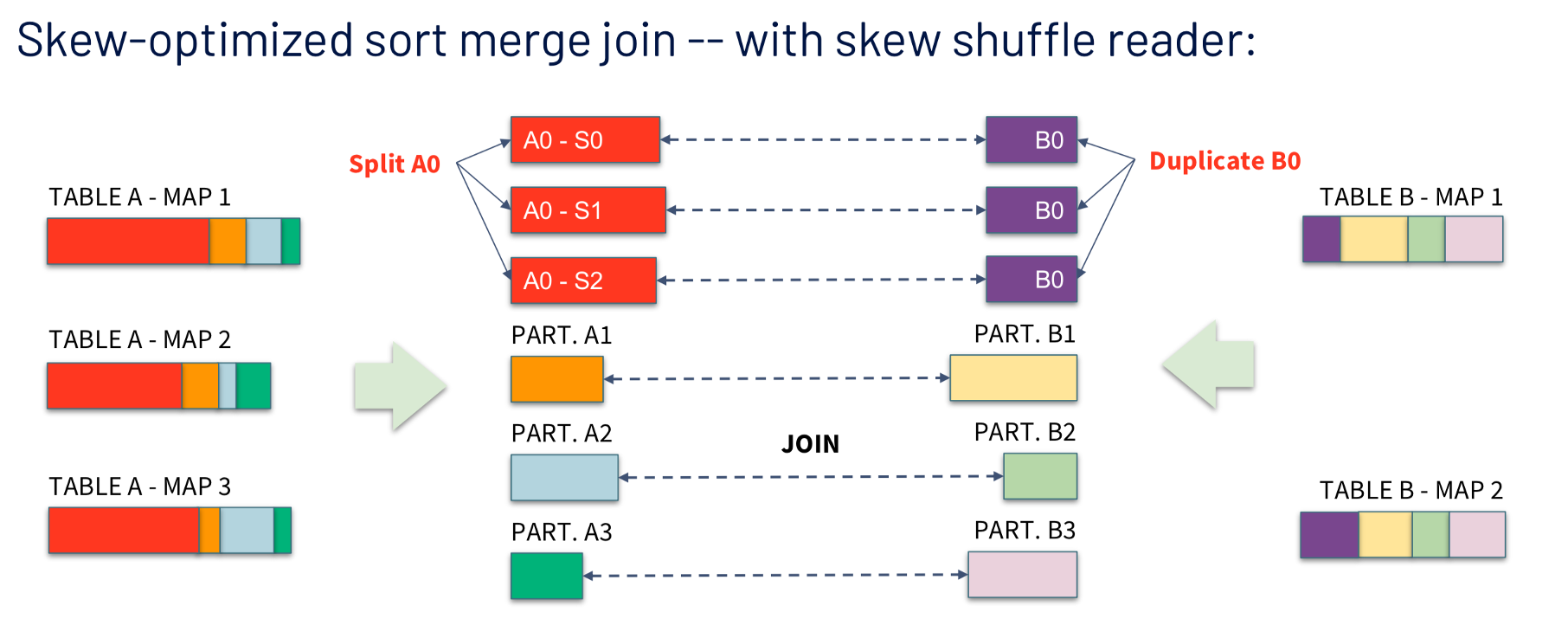
- Join里如果出现某个key的数据倾斜问题,那么基于上就是这个任务的性能杀手了。在AQE之前,用户没法自动处理Join中遇到的这个棘手问题,需要借助外部手动收集数据统计信息,并做额外的加盐,分批处理数据等相对繁琐的方法来应对数据倾斜问题。而AQE由于可以实时拿到运行时的数据,通过
- 优化Join策略
- AQE可以在Join的初始阶段获悉数据的输入特性,并基于此选择适合的Join算法从而最大化地优化性能。比如从Cost比较高的SortMerge在不超过阈值的情况下调整为代价较小的Broadcast Join。参考示例图:
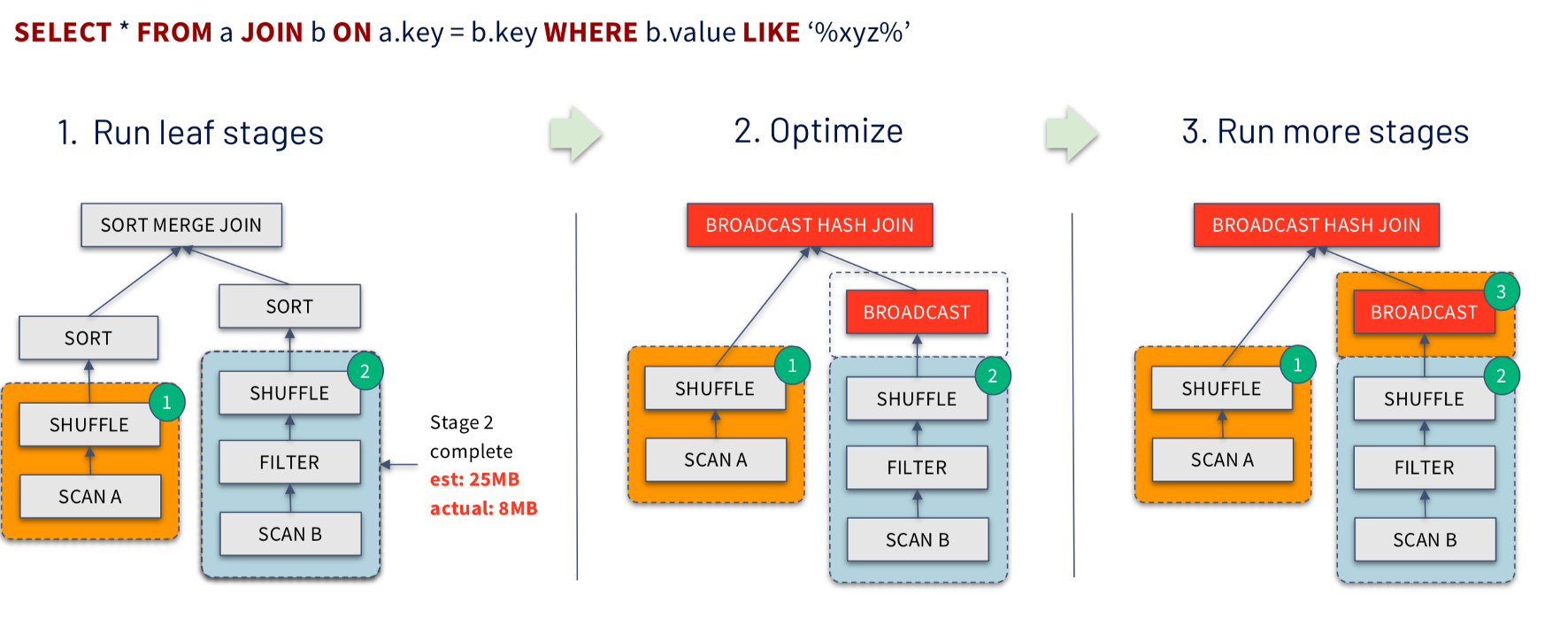
- AQE可以在Join的初始阶段获悉数据的输入特性,并基于此选择适合的Join算法从而最大化地优化性能。比如从Cost比较高的SortMerge在不超过阈值的情况下调整为代价较小的Broadcast Join。参考示例图:
Dynamic Pruning Partition(DPP)
DPP主要解决的是对于星型模型的查询场景中过滤条件无法下推的情况。通过DPP可以将小表过滤后的数据作为新的过滤条件下推到另一个大表里,从而可以做到对大表scan运行阶段的提前过滤掉不必要的partition读取。这样也可以避免引入不必要的额外ETL过程(例如预先ETL生成新的过滤后的大表),在查询的过程中极大的提升查询性能, 感兴趣的同学可以更进一步阅读DPP的详细信息。
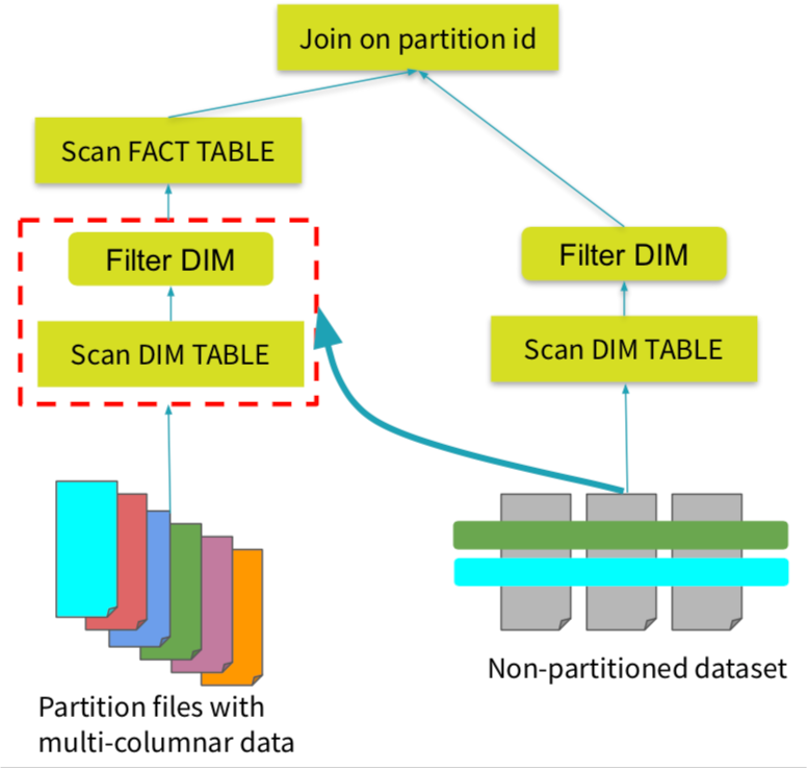
通过Aggragtor注册UDAF
新特性通过用户定制实现的Aggregator来注册实现UDAF,可以避免对每一行的数据反复进行序列化和反序列化来进行聚合,而只需在整个分区里序列化一次 ,缓解了对CPU的压力, 提升性能。假如一个DataFrame有100万行数据共10个paritions,那么旧的UDAF方式的序列化反序列化需要至少100万+10次(合并分区里的结果)。
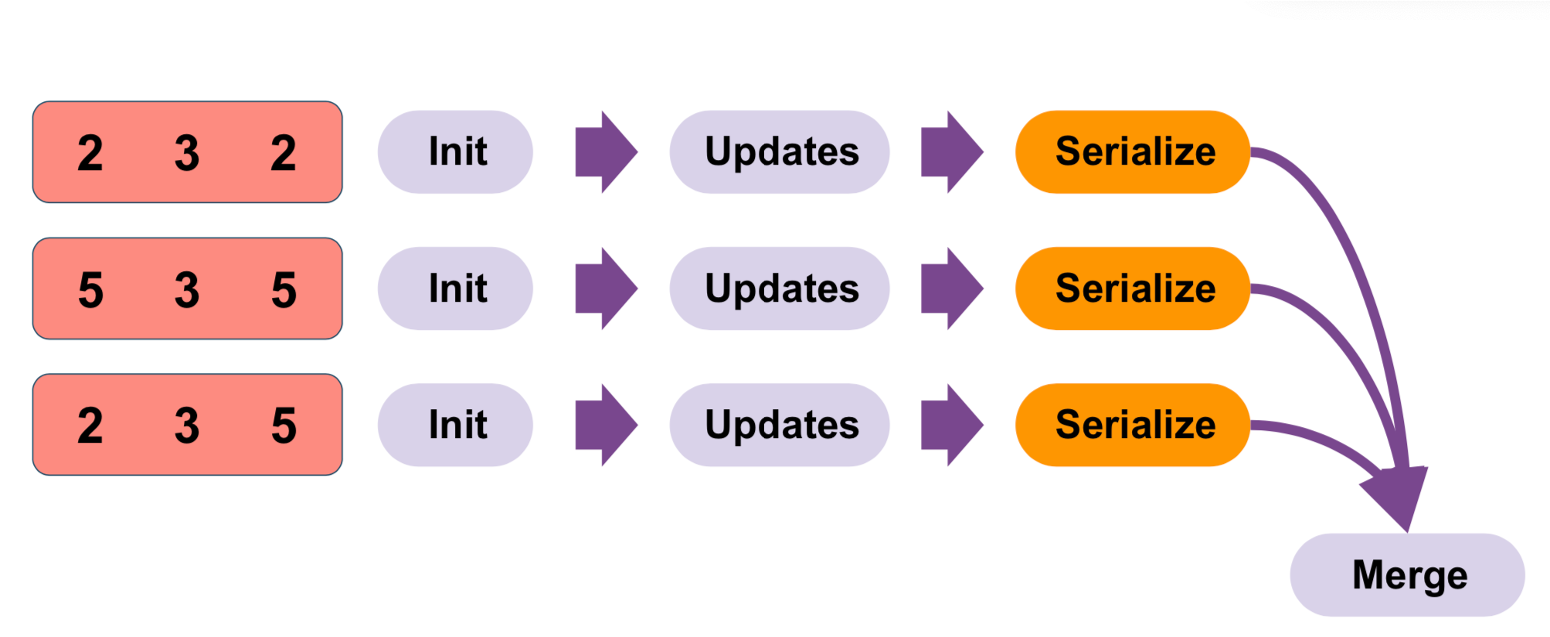 而新的函数只需要10次即可,大大减少整体的序列化操作。其中实现部分最主要的区别体现在UDAF的
而新的函数只需要10次即可,大大减少整体的序列化操作。其中实现部分最主要的区别体现在UDAF的update函数部分:
1
2
3
4
5
6
7
8
9
10
11
//Old Way
def update(buf: MutableAggregationBuffer, input: Row): Unit = {
val agg = buf.getAs[AggregatorType](0) // UDT deserializes the aggregator from 'buf'
agg.update(input) // update the state of your aggregation
buf(0) = agg // UDT re-serializes the aggregator back into buf
}
//New way
def update(agg: AggregatorType, input: Row): AggregatorType = {
agg.update(input) // update the state of your aggregator from the input
agg // return the aggregator
}
更多技术细节部分可以阅读Aggregator 注册UDAF。
文档与监控
Spark 3.0完善和丰富了很多文档及监控信息,来辅助大家更好的进行调优和监控任务的性能动态。
Spark SQL 和 Web UI文档
增加了Spark SQL语法、SQL配置的文档页面 和相关WebUI的文档。
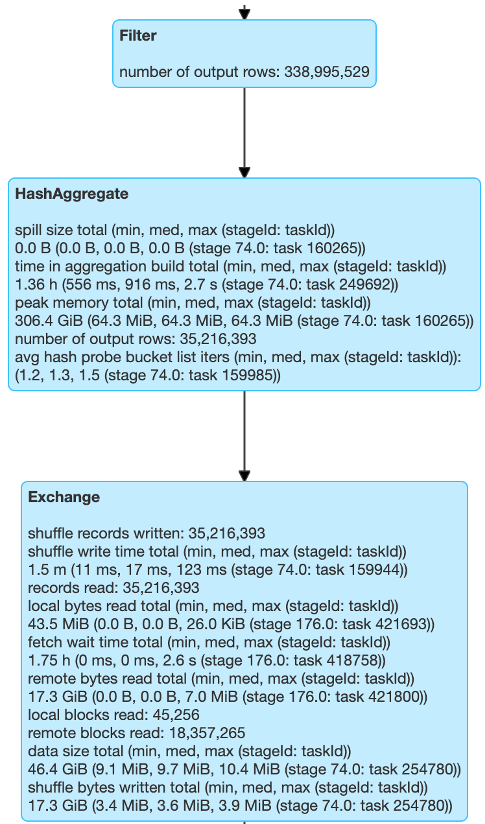
更多的Shuffle 指标
Spark 3.0引入了更多可观察的指标来去观测数据的运行质量。Shuffle是Spark任务里非常重要的一部分,如果能拿到更详细的阶段数据,那么对于程序的调优是很有帮助的。
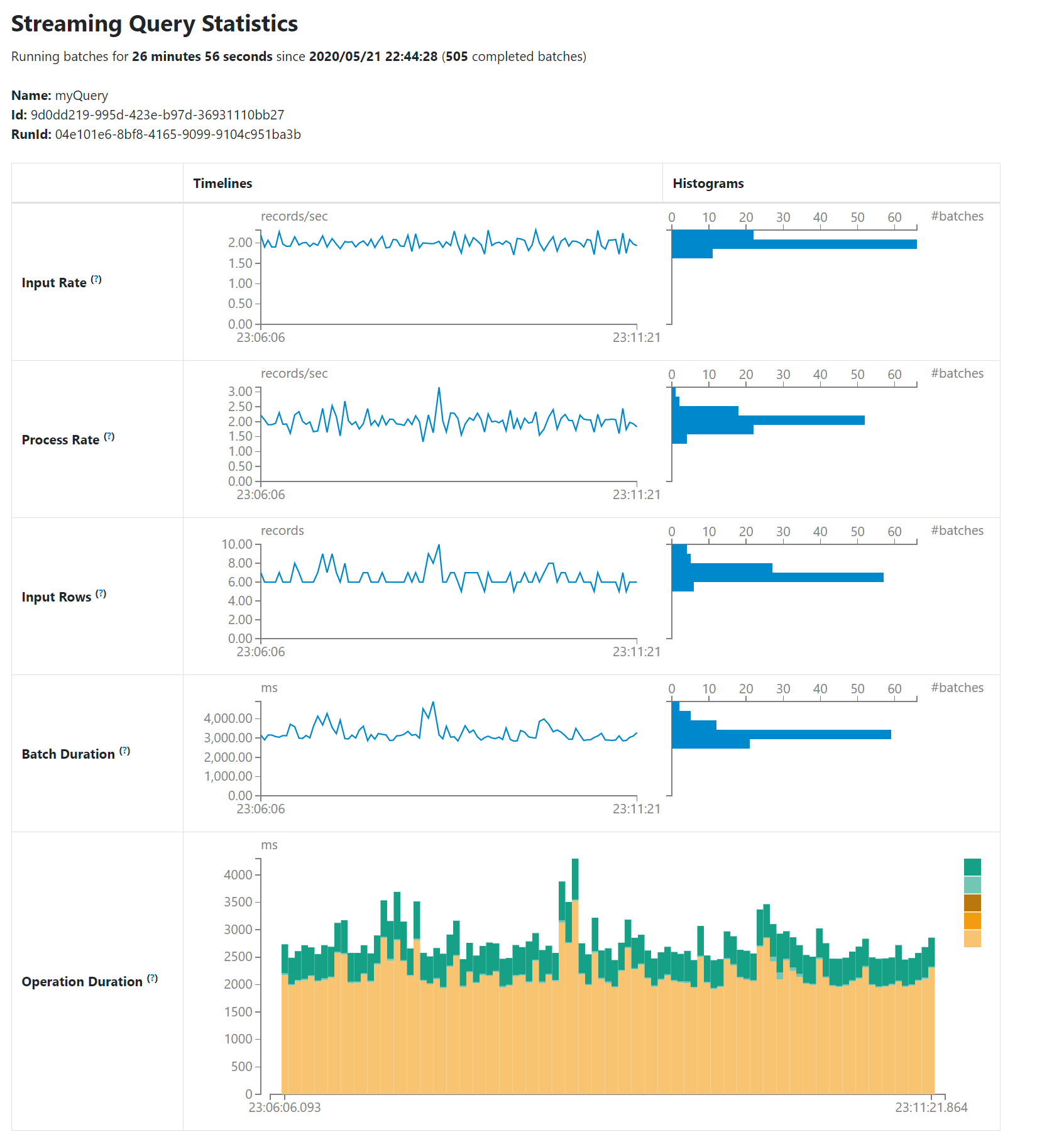
新的Structured Streaming UI
作为社区主推的Spark实时的模块Structured Streaming是在Spark 2.0中发布的,这次在Spark 3.0中正式加入了UI的配置。新的UI主要包括了两种统计信息,已完成的Streaming查询聚合的信息和正在进行的Streaming查询的当前信息, 具体包括Input Rate、 Process Rate、Input Rows、 Batch Duration和Operate Duration,可以辅助用户更进一步观察任务的负载和运行能力。
支持event logs的滚动
Spark 3.0提供了类似Log4j那样对于长时间运行的日志按照时间或者文件的大小进行切割,这样对于streaming长期运行的任务来说比较友好。不然Spark历史服务器打开一个动辄几十GB大小的event log, 打开的速度可想而知。当然,对于Spark的event log不能像其他普通的应用程序日志那样,简单粗暴的进行切割,而是需要保证Spark的历史服务器依赖能够解析已经滚动或者压缩后的日志,并能在Spark UI中展示出来,方便用户进行后续的调优和排查问题操作。具体的细节可进一步阅读相关ticket。
生态圈建设
扩展相关生态圏版本的升级和建设
- 支持Java 11
- 支持Hadoop 3
- 支持Hive 3
Reference
- Spark 3.0 Release Notes
- AQE
- DPP
- UDAF
- CBO
- Spark SQL语法
- Spark SQL配置
- Spark Web UI使用
- Spark Event Logs滚动
- EMR Spark配置
- Parquet嵌套schema问题
- Spark Hive Metastore配置
- EMR 结点标签配置
- Scala 2.12改进
- Spark Aggregation指标改进
- Spark Netty 共享内存Pool
- Spark Task Manager 死锁问题
- Spark Shuffle Block避免网络读取
本网站的文章除非特别声明,全部都是原创。 原创文章版权归数据元素(DataElement)所有,未经许可不得转载!
了解更多大数据相关分享,可关注微信公众号”数据元素“
