前面两篇文章,我们介绍了Hadoop里两个重要的组件MapReduce和HDFS。本文我们一起看一下,作为大数据业内用的比较普遍的YARN的内部机制。
Hadoop 1.x 和 2.x的设计对比
首先让我们从总体上看一下Hadoop 1.x和2.x设计的不同之处。
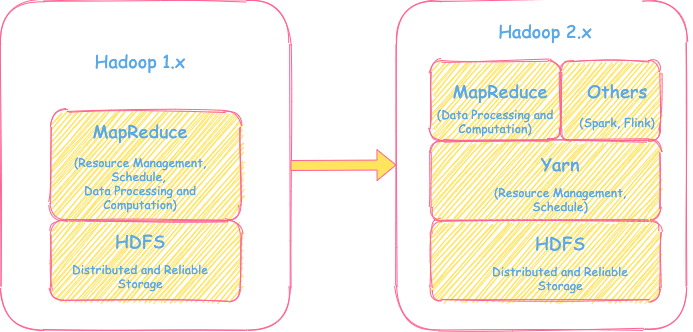
从Hadoop V1和V2的总体设计对比上,可以明显看到几个变化:
- 增加了YARN组件。
- 1.x的Map Reduce将资源的管理调度和数据的处理计算进行了拆解,仅保留了数据处理计算的功能,而用YARN来进行集群的资源管理和调度工作。
- 平台能够支持除了MapReduce以外的其他计算框架,比如Spark, Flink等的计算任务。
为什么会出现YARN?
那么是什么样的原因在Hadoop 2.x里引入YARN这个如今这么受欢迎的组件呢?接下来,我们从更细的架构及工作机制来了解一下背后的故事。
旧版MapReduceV1架构
在MapReduceV1,采用的是经典的Master-Slave架构,可参考下图。
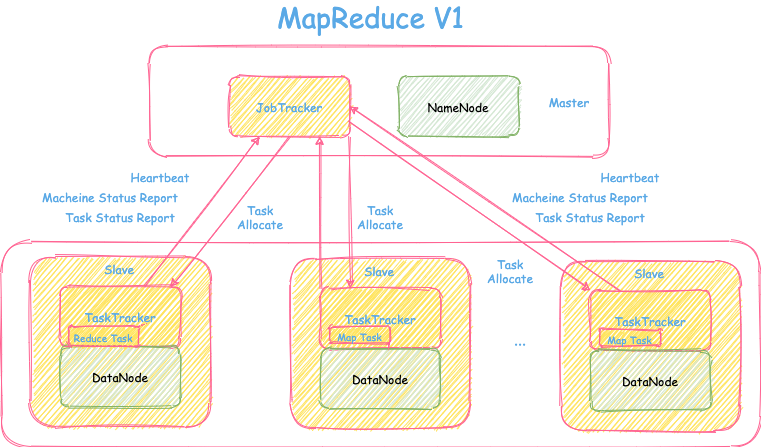
在架构图中存储和计算部署在一个集群里,其中Master机器上有JobTracker和NameNode,而Slave机器上有TaskTracker和DataNode。其中关于存储部分NameNode和DataNode在HDFS文章上有介绍,这里就不再赘述。
MapReduceV1里计算部分由两个重要组件JobTracker和TaskTracker组件:
- JobTracker 职责
- 集群里大脑的角色。
- 负责集群的资源的管理和数据处理任务的调度。
- 负责任务分配与管理: 任务的分发、状态监控、重启等。
- TaskTracker 职责
- 协助JobTracker的工作,具体数据处理任务执行的实体。
- 从JobTracker处领取要执行的任务。
- 向JobTracker发送heartbeat汇报机器的资源状态和任务执行情况。
旧版MapReduceV1存在什么样的问题?
从上面V1架构图来看,整体的Master-Slave工作模式还是比较简单清晰,Hadoop在发布之初也得到业内的快速认可。但随着时间的推移,越来越多的问题凸显出来。
用一个大家熟悉的场景来比喻的话,V1里的JobTracker类似于一个公司的老板,而TaskTracker就好比公司里具体干活的每一个员工。在V1里,老板需要事无巨细的了解人力资源使用情况,为公司接的每个项目分配人力、需要做所有项目的管理工作、并且需要了解每个项目里每个参与的员工具体的工作执行情况: 进度,是否需要换人等等。另外,公司员工可以做的工作的工种也比较单一,只能做Map或者Reduce两类工作。
当公司规模比较小的时候,比如刚刚创业时只有几十人时,老板作为这个公司的大脑层,跟的这么细还能承受住。但是当公司越做越大时,比如膨胀到几千人以后,如果老板还需要每天都了解具体每一项小工作的执行情况,肯定会累的吐血….这也是当时总结出来的V1最多只能支持4000节点的集群规模上限。
总结一下MapReduceV1存在的问题:
- JobTracker是单点瓶颈及故障,负担太重。
- 只支持Map、Reduce两类计算task类型,和Hadoop本身的框架耦合比较重,无法支持其他的计算类型,复用性较差。
- 资源划分是按Map Slot、Reduce Slot进行划分,没有考虑Memory和Cpu的使用情况,资源利用有问题(容易OOM或者资源浪费)。
新组件YARN的架构
为了解决上面的问题,Hadoop在2.x里重新做了设计,引入新的组件YARN(Yet Another Resource Negotiator)。其中最重要的变化是把V1里JobTracker职责资源管理调度和数据计算任务管理两部分进行了拆分,YARN主要用来负责资源管理调度,与具体的计算任务无关。而2.x里的MapReduce只负责Hadoop相关的数据处理和计算等相关工作。YARN组件的出现,极大提升了Hadoop组件的复用性,能够很容易支持其他计算框架的任务。
我们具体看一下YARN的架构:
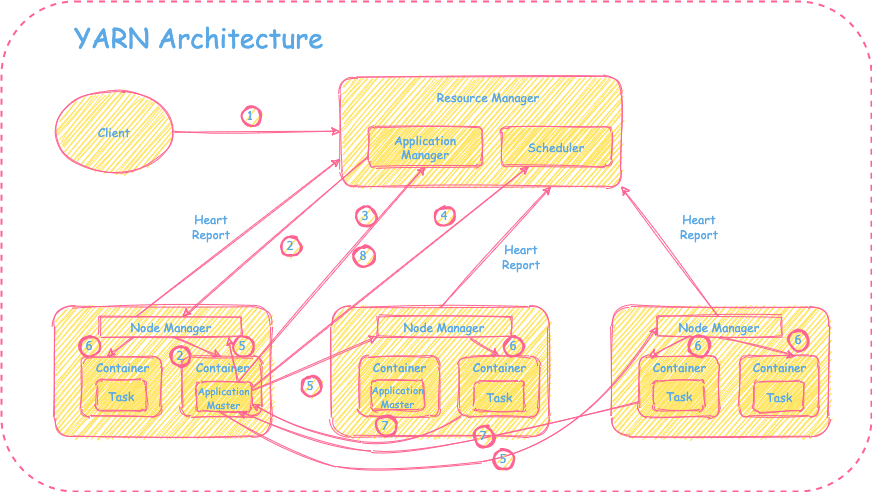
YARN的组件介绍
Resource Manager
职责: 拥有整个集群资源的全局or上帝视角,主要负责整个集群的所有应用程序的资源调度,并不负责每个应用程序执行状态的管理。
Resource Manager包含的重要组件:
- ApplicationManager
职责: 负责接受客户端或者服务端应用的请求,为应用分配第一个containerApplicationMaster,并负责监控ApplicationMaster的状态,启动及失败重启等操作。
- Scheduler
职责: 一个单纯的资源调度服务。根据应用程序需要的资源请求以及集群的资源情况,为应用程序分配对应的资源。并不关心应用本身的执行情况。分类:- FIFO Scheduler: 先进先出,不考虑应用程序本身的优先级和资源使用情况
- Capacity Scheduler: 将资源分成队列,共享集群资源但需要保证队列的最小资源使用需求
- Fair Scheduler: 公平的将资源分给应用,保证应用使用的资源是均衡的。
Container
概念: YARN里最小的一组分配的资源粒度,目前主要是针对CPU和Memory的资源分配。
所有的MapReduce任务和其他分布式任务都是跑在Container里。
Node Manager
职责:
- 负责监控本机的资源和健康情况,与Resource Manager通信机器资源情况和心跳汇报。
- 负责监控并管理Container的生命周期
- 响应Resource Manager的请求创建Container
- 监控Container的资源使用和健康情况,失败重启或者失控Kill等操作
- 不关心具体跑在Container里的任务情况。
ApplicationMaster
职责:
- 负责与Resource Manager和Node Manager沟通协调申请资源以及释放资源
- 负责整个应用的执行情况管理,监控/收集task执行进度结果,创建或者重启task
YARN的优势
在以上组件的介绍中,可以看到,基本每个组件都是各司其职,不再像V1.0里的JobTracker一样身上的担子太重成为整个集群的瓶颈。而资源调度组件与计算任务管理分开不再和MapReduce部分高度耦合,极大提升了资源调度组件的复用性,因此整个YARN的推广就更自然顺畅。因为不同的计算框架任务(Hadoop, Spark, Flink等)都可以非常方便地由YARN来进行调度,只需任务对应的Application Master可以跑在container即可。
YARN里应用执行流程
接下来,我们看一下客户端提交应用程序后,在YARN里整体执行情况:
① 客户端向ResourceManager提交应用请求
② ApplicationManager为该应用向NodeManager申请第一个Container,在里面创建应用的ApplicationMaster并监控其状态
③ ApplicationMaster在ApplicationManager里注册自己
④ ApplicationMaster向Scheduler申请自己需要的资源
⑤ 申请到资源后,ApplicationMaster会去向对应的NodeManager要求创建对应需要的Container
⑥ NodeManager创建对应的Container,并启动容器,运行相应的任务
⑦ 各个容器向ApplicationMaster汇报任务执行进度和状态,便于ApplicationMaster掌握应用执行情况进行管理(重启or Kill)
⑧ 任务执行完毕或者失败后,ApplicationMaster会向ResourceManager汇报状态,注销自己并释放资源
YARN的HA
YARN是通过ResourceManager主备双活+Zookeeper锁节点方式来保证HA的,是一种常见的HA机制,这里不再赘述。稍需要注意的是,ResourceManager的相关的作业信息是存放在Zookeeper中。当发生主备切换时,新的active的ResourceManager会从Zookeeper中读取信息,然后再从NodeManager里收集到的机器资源情况,重新构建整体的集群资源情况。
Reference
本网站的文章除非特别声明,全部都是原创。
原创文章版权归数据元素(DataElement)所有,未经许可不得转载!
了解更多大数据相关分享,可关注微信公众号”数据元素“
