Spark Shuffle 是什么
Spark Shuffle是根据数据处理需求将数据按着某种方式重新混洗,以便于后面的数据处理。比如reduceByKey()的操作,通过先将数据按照key进行重新分区以后,然后对每个key的数据进行reduce操作。
Spark Shuffle共包括两部分:
- Spark Shuffle Write
- 解决上游输出数据的分区问题
- Spark Shuffle Read
- 通过网络拉取对应的分区数据,重新组织,然后为后续的操作提供输入数据
Spark Shuffle 要解决的问题
我们先从总体的角度来看一下Spark Shuffle要解决哪些问题,以及是大致的解决方案是什么。
- 如何灵活支持不同计算的场景下不同的需求?排序、聚合、分区?
- 通过灵活的框架设计来满足不同的需求
- 如何应对大数据量的情况下面临的内存压力?
- 通过
内存 + 磁盘 + 数据结构设计来解决内存问题
- 通过
- 如何保证Shuffle过程的高性能问题?
- 减少网络传输
- map端的reduce
- 减少碎小文件
- 按partitionId进行排序并合并多个碎文件为一个,然后加上分区文件索引供下游使用
- 减少网络传输
Spark Shuffle的框架
接下来,我们一起看看Spark Shuffle在Write和Read两个阶段是如何设计对应的框架,来解决上面阐述的问题。
Spark Shuffle Write框架
在Shuffle Write阶段,数据操作需要提供的是排序、聚合和分区三个数据功能。但可能在数据场景里,需要的功能只是其中一个或者两个,因此Spark Shuffle的Write整体框架设计成“map --> combine(可选)--> sort(可选) --> partitions”。具体的框架如下图所示:
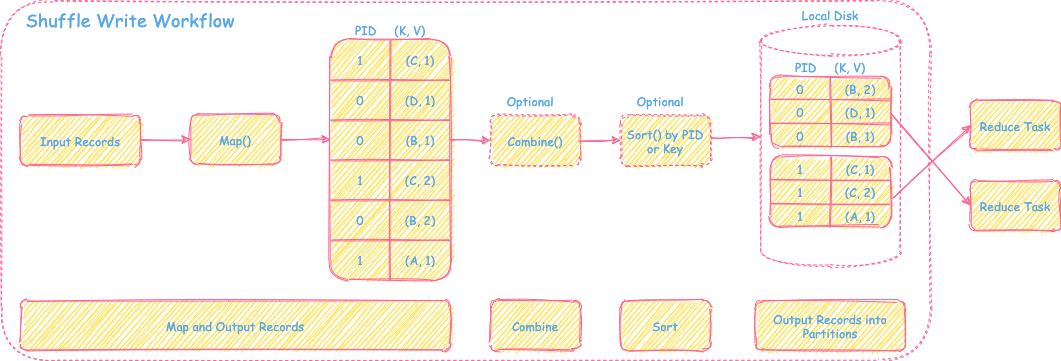
如上图所示,根据Write阶段不同的数据处理需求,Spark进行不同的流程选择和数据结构设计来解决计算需求、内存压力和性能问题。接下来会进行每个场景详细的分解介绍。
1) 仅需要map,不需要combine和sort的场景

过程
对于输入的record,经过map运算后,会输出record对应的partitionId和map后的数据直接放到内存里其对应分区的buffer里,当buffer数据满了以后会直接flush到磁盘上对应的分区文件里。因此一个map task的每个分区对应一个buffer和磁盘上的一个文件。
命名
BypassMergeSortShuffleWriter
优点
- 速度快,操作是在内存中进行,直接将map处理后的record输出到对应的分区文件。
缺点
- 每个分区需要对应内存的一个buffer,如果分区个数较多,那么占用的内存就会比较大。另外,每个分区对应一个输出文件,当分区个数过多时,文件打开数,以及下游Shuffle Read时的连接数都会很大。因此容易造成资源不足的情况发生。
适用场景
- 通过优缺点分析,可以看到,这种处理方式只适合分区个数比较小的情况下(可以通过
spark.shuffle.sort.byPassMergeThreshold设置),速度比较快。另外也不需要额外的combine和sort的场景,比如简单的partitionBy(), groupBy()类似的transformation操作。
内存消耗
- 主要是每个分区对应的buffer的内存占用
2) 需要map,需要combine的场景
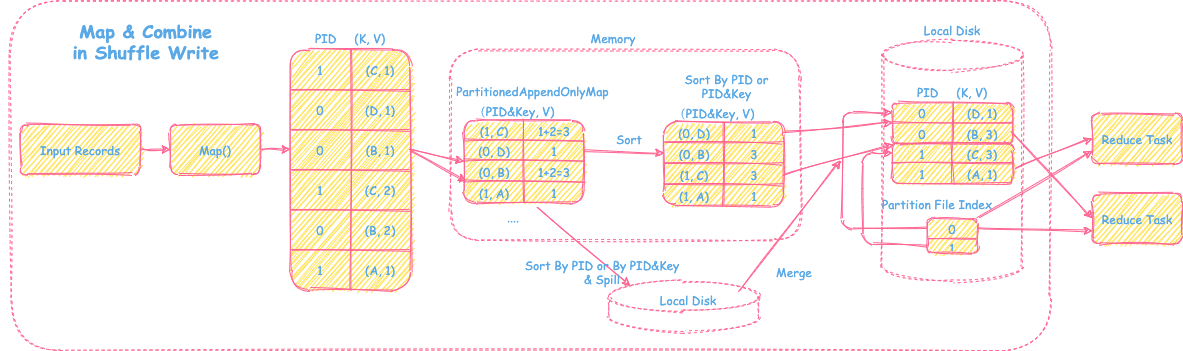
过程
1) Map和在线聚合
对于输入的record,经过map运算后,会放进一个类似HashMap的数据结构里(PartitionedAppendOnlyMap,后面会对这个结构进行介绍),如果HashMap里key存在,那么会将该record的值和对应结构里的value进行combine操作,然后更新key在这个HashMap里的数值,实现在线聚合的功能。否则,直接将record的值更新到HashMap里即可。
其中这里的key = partitionId + record key。
2) Sort&Spill
当HashMap里不够存放时,会先进行扩容,扩容为原来的两倍。如果还存放不下,然后会将HashMap里的record排序后放入磁盘里。然后清空进行HashMap,继续进行后续的在线聚合操作。
其中这里对record进行排序的key:
- 如果需要map端按照record key排序,那么这里排序的
key=partitionId+record key - 否则,这里的排序
key=partitionId
3) Sort&Merge
在输出文件时,会将Spill到磁盘的和内存里的数据,进行Sort和Merge操作,然后按PartitionId输出数据。最终会生成一个输出文件(存放该map task产生的所有的分区文件) + 分区数据索引文件供下游Shuffle Read使用。
命名
SortShuffleWriter的一种场景
优点
- 通过设计的HashMap数据结构支持在线聚合的方式处理map端的combine操作,不用等所有的map数据都处理结束,提升性能,也节省了内存空间。
- 利用内存+磁盘的方式来可以解决大数据量下面临内存不足的问题。
- 一个map task只输出一个总的分区文件和分区索引,减少了碎文件的个数,提升了I/O资源利用率和性能,对下游也比较友好。适合分区数据较多的Shuffle情况。
缺点
- 在线聚合的方式,需要对record一条一条的处理,相对Hadoop将map全处理结束后,再统一的进行聚合的方式相比,无法定制灵活的聚合方式。
- 直接通过原生HashMap的方式的话,会存在聚合后,再次copy到线性数组结构时进行排序引发的额外的copy和内存占用问题。需要设计更好的数据结构来支持高效的combine和sort操作。
适用场景
- 大分区且需要map端combine的操作,比如reduceByKey(), aggregateByKey()等。
数据结构PartitionedAppendOnlyMap
- 实现
HashMap + Array的结合体。- 仅支持对数据的增加和更改操作(Append Only),不支持删除操作。
- 底层是一个线性数组,通过对key(partitionId + record key)的hash,然后按照hash值在数组中通过探测的方式找到存放和读取的位置
- 如果hash值对应的位置没有存放数据,那么就把对应的数据放进去。
- 否则,看临近的下一个位置是否是空的,依次探测,直到找到一个空的位置放进去即可。
- 读取的时候也是类似的根据hash值探测方式读取,然后将值combine以后再update回去。
- 扩容时将底层数组再扩大一倍,然后对数组里的数据再rehash重新放置。
- 局部排序: 将数组的数据都移到最前方的位置,然后按照对应的partitionId或者partitionId+key进行线性数组排序。
- 全局排序: 再将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局排序合并操作即可。
- 优点
- 不需要额外占用内存空间来进行HashMap结构到线性数组结构的copy转化过程。
内存消耗
- 在线聚合需要的HashMap数据结构 + 中间聚合过程用户代码所占用的数据空间 + 排序所占用的空间
- 取决于输入数据量的大小和用户聚合函数的复杂性
3) 需要map,需要sort,不需要combine的场景
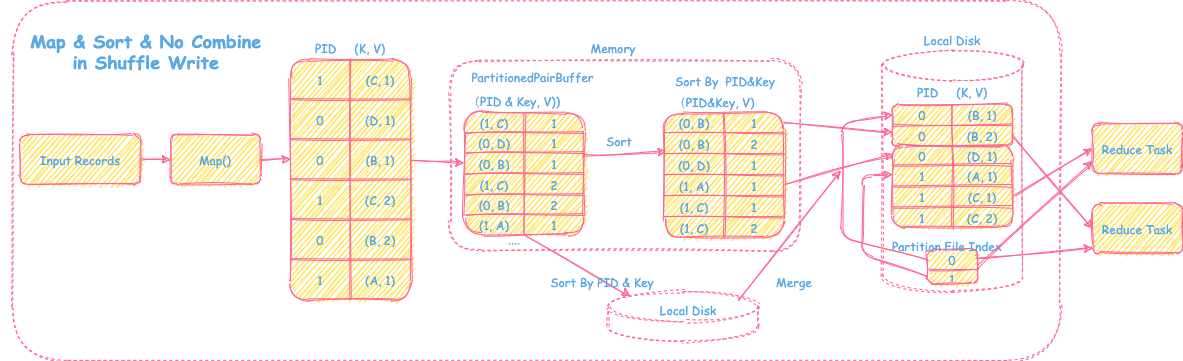
过程
1) Map
对于输入的record,经过map运算后,会被放入内存一个类似线性数组的结构里(PartionedPairBuffer,下面会介绍该数据结构)
2) Sort&Spill
当数组里放不下map后的数据时,会先进行扩容,扩容为原来的两倍,并移动数据到新分配的空间。如果还存放不下,会把array的record进行排序后放入磁盘。然后清空数据,继续后续的map数据存储。
其中这里对record进行排序的key:
- 如果需要map端按照record key排序,那么这里排序的
key=partitionId+record key - 否则,这里的排序
key=partitionId
3) Sort&Merge
在输出文件时,会将Spill到磁盘的和内存里的数据,进行Sort和Merge操作,然后按PartitionId输出数据。最终会生成一个输出文件(存放该map task产生的所有的分区文件) + 分区数据索引文件供下游Shuffle Read使用。
命名
SortShuffleWriter的一种场景
优点
- 通过一个数组的结构来支持map端按照partitionId或者partitionId + key的方式进行排序。
- 同样的利用内存+磁盘的方式来解决内存不足的问题。
- 一个map task只输出一个总的分区文件和分区索引,减少了碎文件的个数,提升了I/O资源利用率和性能,对下游也比较友好。适合分区数据较多的Shuffle情况。
缺点
- 需要额外的排序过程
适用场景
- 大分区且需要map端按key进行sort且不需要combine的场景,比如sortByKey()
- 或者大分区限制下map端的不需要combine的场景,partitionBy(1000)
数据结构PartitionedPairBuffer
- 实现
- 底层是特殊array。
- 一条record会占用array里两个相临空间,第一元素是
partitionId+record key,第二元素是recordvalue。 - 扩容时将底层数组再扩大一倍,然后对数组里的数据copy到新的空间里。
- 局部排序直接将数组里的数据然后按照对应的partitionId或者partitionId+key进行线性数组排序。
- 全局排序再将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局归并排序合并操作即可。
- 优点
- 支持内存+磁盘的方式,可以支持按partitionId 或者 partitionId + record key的方式进行排序。
内存消耗
- 存放数组的sort所需要的数组 + 排序所占用的空间
- 取决于输入数据量的大小
4) 更进一步优化Serialized Shuffle
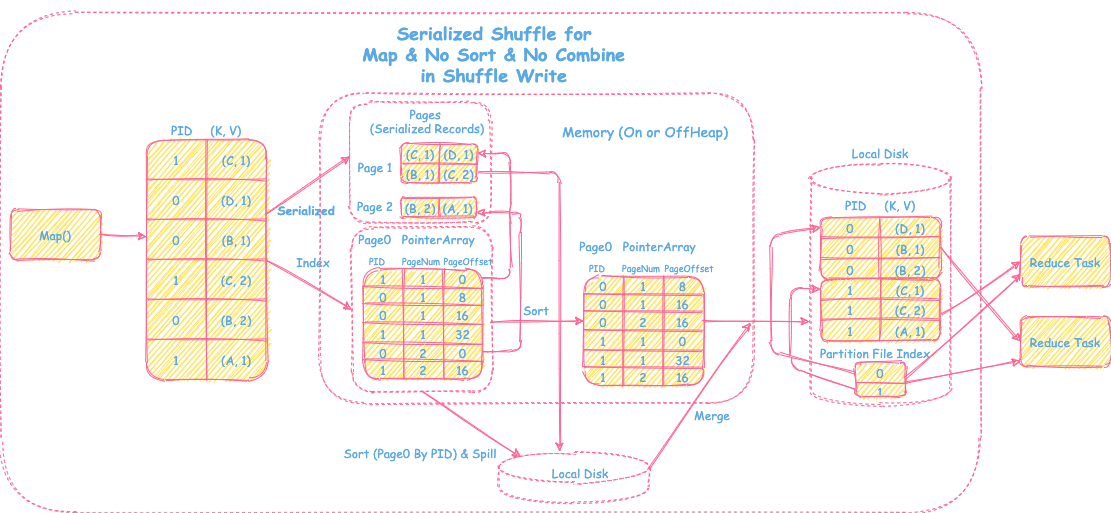
过程
1) Map&Serialized&Index
- 输入数据通过map处理后得到带分区的<K, V> record,然后会将record序列化后放到相应的pages中,并在page0中记录record在对应的page的offset信息,以便能够快速找到record,其中page0里会包括partitionId, pageNum和pageOffset。
2) Sort&Spill
- 按照page0里记录的partitionId进行排序,当内存中放不下page0和相应的存放序列化数据的pages,会将pages和排序后的page0先spill到磁盘上,解决内存压力问题。
3) Sort&Merge
- 当map端的数据都处理结束后,将内存排序后的page0+pages数据和磁盘上spill的文件及数据按照partitionId做全局的归并排序,最后输出一个文件包含排序后的所有分区数据+分区索引文件供下游reduce task使用。
命名
UnsafeShuffleWriter的一种场景
优点
- 减少memory占用
- Serialized Shuffle是针对map里不需要聚合和排序但是partition个数较多的情况下一种优化。前文中提到对于这种场景,用的是数组结构,存放的是普通的record的Java对象。当record比较大时,非常占用内存,也会导致GC频繁。Serialized Shuffle将record序列化以后放在内存,减少内存的占用。
- 提高性能
- 排序时只需要对record的索引page0按照partitionId进行排序,不涉及到具体record的操作,不会涉及额外的序列化反序列化操作,提高排序性能。
- 分页技术可以使用非连续的内存空间
- 相对于数组,分页的方式不要求所有的pages分配的空间是连续的,因此可以充分利用零碎内存空间。
- 可以使用堆外内存
- page0和pages上的序列化数据可以使用堆外内存技术来存放数据。
缺点
- 不支持map端的排序和聚合(因为record被序列化了)
- 分区个数有限制需要小于224 (page0里partitionId用24bits来表示)
- 单个serialized需要小于128M
适用场景
- 适用于map端不需要排序和聚合,partition个数较大,record本身也比较大的场景
数据结构PointerArray
- 实现
- 实质上就是一个Long Array
- 前24bits表示的partitionId,接着13bits表示pageNum,最后的27bits表示的是在page里Offset
- 用来存放序列化后的record在对应的哪个page及page中的offset
- 优点
- 占的内存空间小,也能快速定位序列化后的record
内存消耗
- page0 + 数据record序列化后pages的大小 + 排序占用的空间
- 取决于输入数据量的大小 + record本身序列化后的大小
Spark Shuffle Read框架
Spark Shuffle Read阶段主要解决的是从上游Map产生的数据里拉取对应分区的数据,然后进行重新组织和计算,为后续的操作transformation提供输入数据。主要包括拉取分区数据 --> Aggregate Func(可选) --> Sort(可选)三步计算顺序。
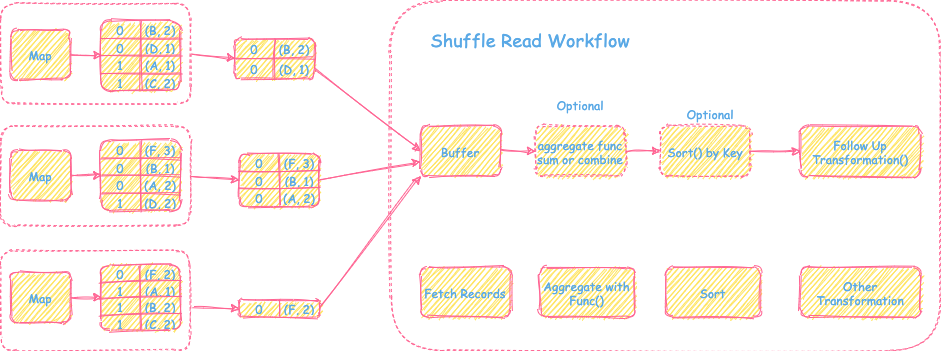
如上图所示,是一个Spark Shuffle Read比较通用的框架流程。接下来会为不同的数据场景需求来分析Spark Shuffle Read阶段具体的实现方式和细节。
1) 不需要聚合操作,也不需要sort操作
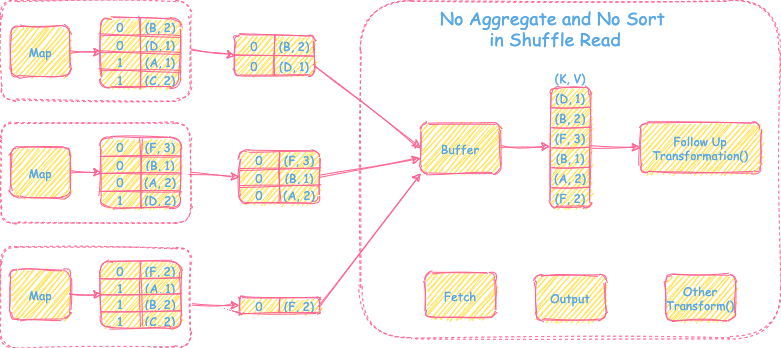 过程
过程
- 直接从上游Map端拉取reduce task对应的分区文件到buffer里,输出为<K, V>的record然后直接继续后续的transformation操作。
优点
- 内存消耗小,实现简单。
缺点
- 不支持聚合和排序操作。
适用场景
- reduce端不需要聚合和排序的场景,比如partitionBy()。
内存消耗
- 拉取数据的buffer空间
2) 只需要sort操作,不需要聚合操作
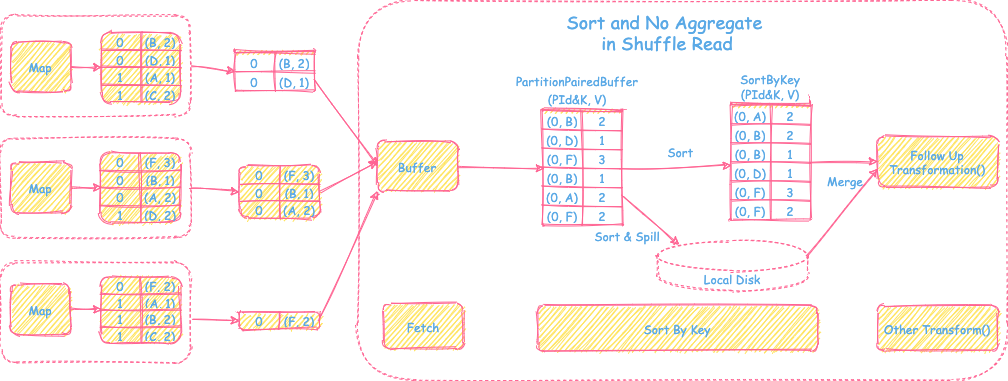 过程
过程
- 直接从上游Map端拉取reduce task对应的分区文件放到内存特殊数组
PartitionPairedBuffer里(具体数据结构会在下文介绍),当数组里的数据装满后会按照partitionId + record key进行排序,spill到磁盘。然后清空数组继续装拉取过来的数据。当所有从map端拉取的数据都处理完后,会将内存里的数据和spill到磁盘里的数据进行全局归并排序,最后交给后面进行其他的transformation操作。
优点
- 支持reduce端的sort操作
- 支持内存+磁盘的方式排序,解决内存不足问题,可以处理大数据量
缺点
- 不支持reduce端聚合操作
- 排序增加时延
适用场景
- reduce端只需要排序不需要聚合的场景,比如sortByKey()
数据结构PartitionPairedBuffer
同上文中的数据结构
- 实现
- 底层是特殊array。
- 一条record会占用array里两个相临空间,第一元素是
partitionId+record key,第二元素是recordvalue - 扩容时将底层数组再扩大一倍,然后对数组里的数据copy到新的空间里。
- 局部排序直接将数组里的数据然后按照对应的partitionId或者partitionId+key进行线性数组排序。
- 全局排序再将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局归并排序合并操作即可。
- 优点
- 支持内存+磁盘的方式,可以支持按partitionId 或者 partitionId + record key的方式进行排序。
内存消耗
- 存放数组的sort所需要的数组 + 排序所占用的空间
- 取决于输入数据量的大小
3) 需要聚合操作,需要sort或者不需要sort的操作
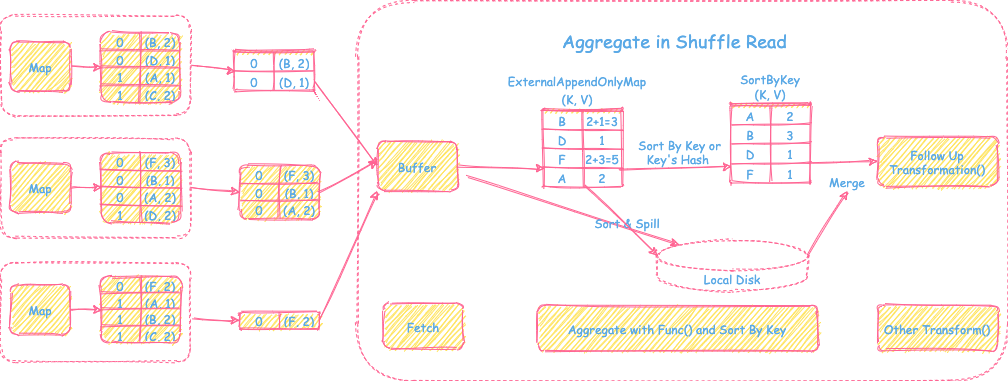 过程
过程
- 从上游map端拉取的reduce tasks对应的分区文件的数据到buffer后,会建立一个HashMap的数据结构
ExternalAppendOnlyMap对buffer的record进行在线聚合。如果HashMap数据放不下后,会先进行扩容,如果内存还放不下。会先按照record的key进行排序,然后spill到本地磁盘里。最终map端的数据处理结果以后,会将磁盘里spill的文件和内存中排好序的数据进行全局的归并聚合,再交给后面的其他的transformation操作。
优点
- 支持reduce端的聚合和sort操作
- 支持内存+磁盘的方式在线聚合和排序,解决内存不足和等所有map的数据都拉取结束再开始聚合的时延问题,可以处理大数据量
缺点
- 聚合排序增加内存消耗和时延
适用场景
- reduce端需要聚合的场景,比如reduceByKey(), aggregateByKey()
数据结构ExternalAppendOnlyMap
同前文中PartitionedAppendOnlyMap数据结构,是一个类似的HashMap结构,只不过PartitionedAppendOnlyMap的key是partitionId + record key, 而ExternalAppendOnlyMap的key是record key。
- 实现
HashMap + Array的结合体。- 仅支持对数据的增加和更改操作(Append Only),不支持删除操作。
- 底层是一个线性数组,通过对key(record key)的hash,然后按照hash值在数组中通过探测的方式找到存放和读取的位置
- 如果hash值对应的位置没有存放数据,那么就把对应的数据放进去。
- 否则,看临近的下一个位置是否是空的,依次探测,直到找到一个空的位置放进去即可。
- 读取的时候也是类似的根据hash值探测方式读取,然后将值combine以后再update回去。
- 扩容时将底层数组再扩大一倍,然后对数组里的数据再rehash重新放置。
- 局部排序: 将数组的数据都移到最前方的位置,然后按照对应的key的hash值或者key(需要按照key排序的场景)进行线性数组排序。
- 如果按照key的hash值排序,当hash值相等时,会进一步看key是否相等,来判断是否是hash冲突引发的相等。
- 全局排序: 在将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局排序合并操作即可。
- 优点
- 不需要额外占用内存空间来进行HashMap结构到线性结构的copy转化过程。
内存消耗
- 在线聚合需要的HashMap数据结构 + 中间聚合过程用户代码所占用的数据空间 + 排序所占用的空间
- 取决于分区输入数据量的大小和用户聚合函数的复杂性
Spark Shuffle的前世今生
Spark的Shuffle在Write和Read两阶段有今天灵活的框架设计也是一步步不断完善的努力,我们一起来回顾一下它的前世今生。
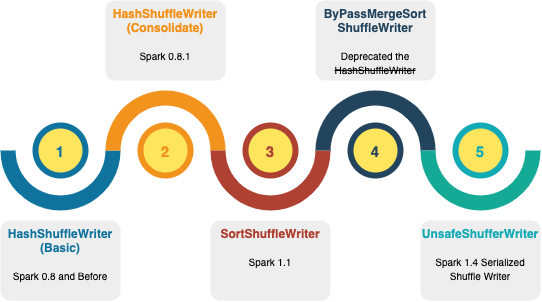
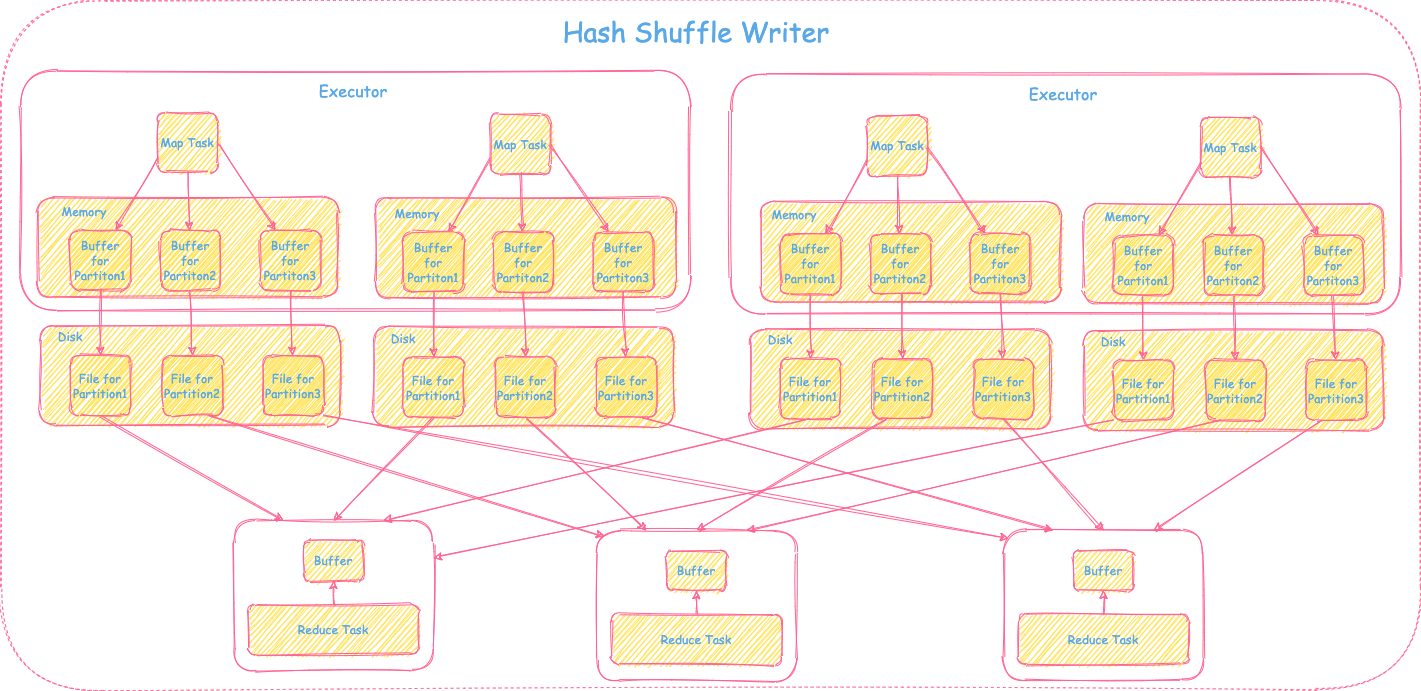
1) Spark 0.8 之前HashShuffleWriter
在Spark 0.8以前用的是basic的HashShuffleWriter,整体的实现就是Shuffle Write框架里介绍是仅需要map,不需要combine和sort的场景。实现上比较简单直接,每个map task按照下游reduce tasks个数即reduce分区个数,每个分区生成一个文件写入磁盘。如果有M个map tasks, R个reduce tasks,那么就会产生M * R个磁盘文件。因此对于大分区情况非常不友好,会生成大量的碎文件,造成I/O性能下降,文件连接数过大,导致resource吃紧,进而影响整体性能。具体可参考下图:
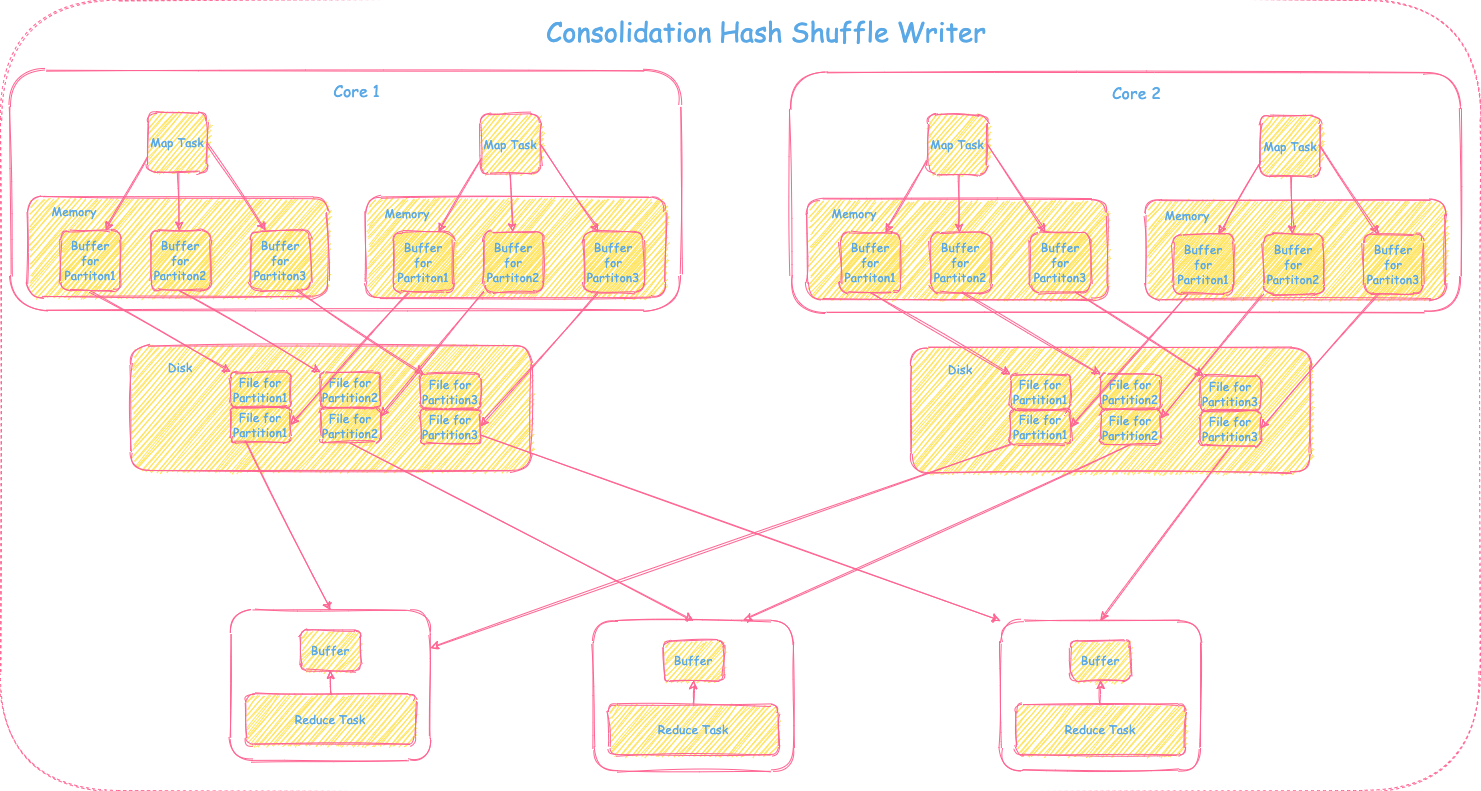
2) Spark 0.8.1 引入文件Consolidation的HashShuffleWriter
由于basic的HashShuffleWriter生成的碎小文件过多,为了解决这个问题引入了文件Consolidation机制。在同一个core上运行的所有的map tasks对应的相同的分区数据会写到相同的buffer里最终对应分区的一个分区文件。如果有M个map tasks, R个reduce tasks,C个cores,那么最终会产生C * R个磁盘文件。如果C比M小,那么对比basic的HashShuffleWriter,文件个数有所下降,性能会得到提升。具体过程可参照下图:
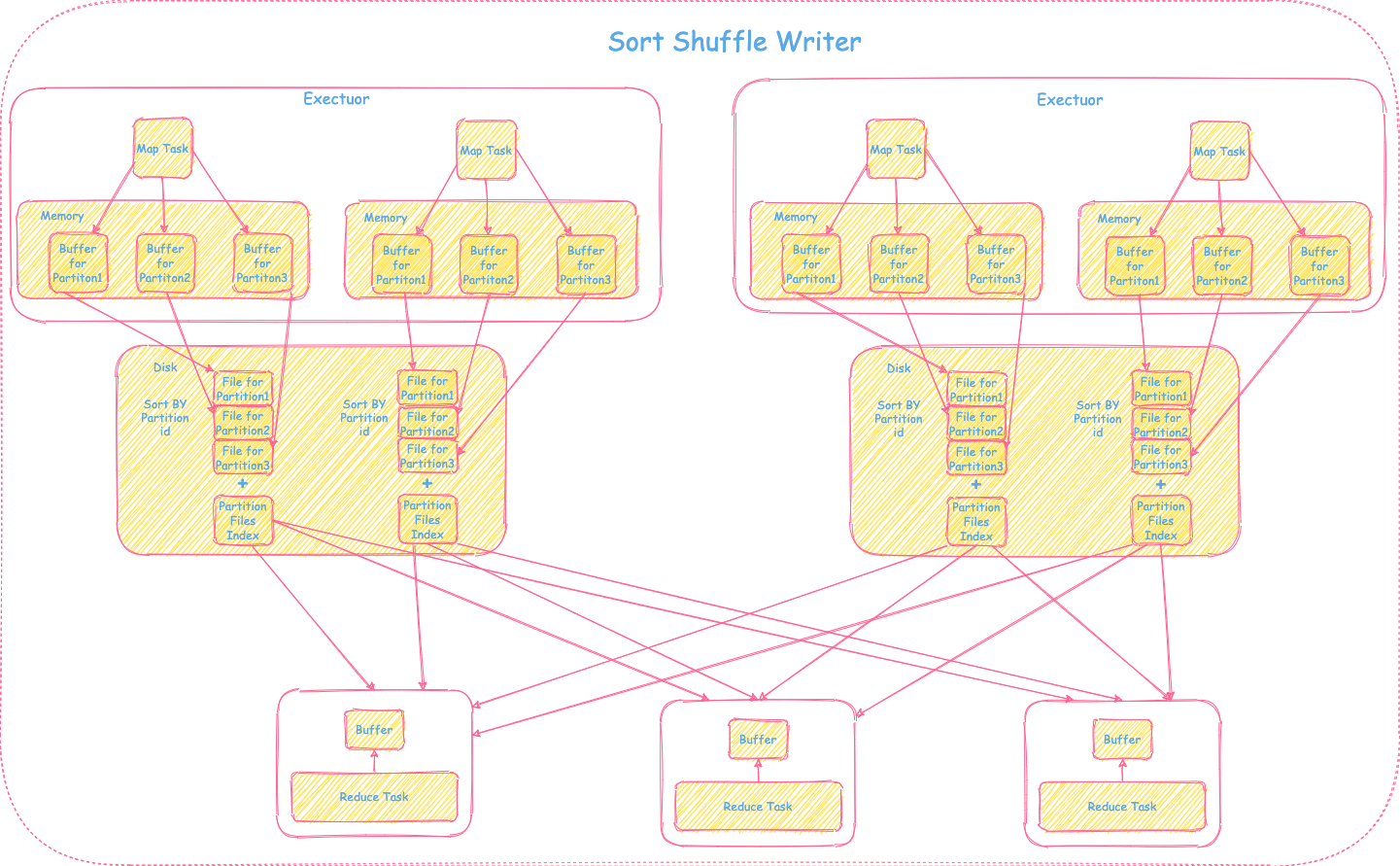
3) Spark 1.1 引入SortShuffleWriter
虽然Consolidation的机制在一定程度上减少文件个数,但是当cores和reduce的task过多的时候一个map task依然会产生大量的文件。在Spark 1.1里首次引入了基于sort的shuffle writer,整体的实现是Shuffle Writer框架里介绍的需要map,需要sort,不需要combine的场景。每个map task的输出数据会按照partitionId排序,最终一个map task只会输出一个分区文件包括这个map task里的所有分区数据 + 分区索引文件供下游shuffle read使用,大大减少了文件个数。具体过程可参照下图:
4) BypassMergeSortShuffleWriter
SortShuffleWriter的引入大大减少了文件个数,但是也额外增加了按partitionId排序的操作,加大了时延。对于分区个数不是太大的场景,简单直接的HashShuffleWriter还是有可借鉴之处的。BypassMergeSortShuffleWriter融合了HashShuffleWriter和SortShuffleWriter的优势,每个map task首先按照下游reduce tasks的个数,生成对应的分区数据和分区文件(每一个分区对应一个分区文件),在最终提供给下游shuffle read之前,会将map task产生的这些中间分区文件做一个合并(Consolidation),只输出一个分区文件包含所有的分区数据 + 分区索引文件供下游shfulle read使用。具体过程可参照下图:
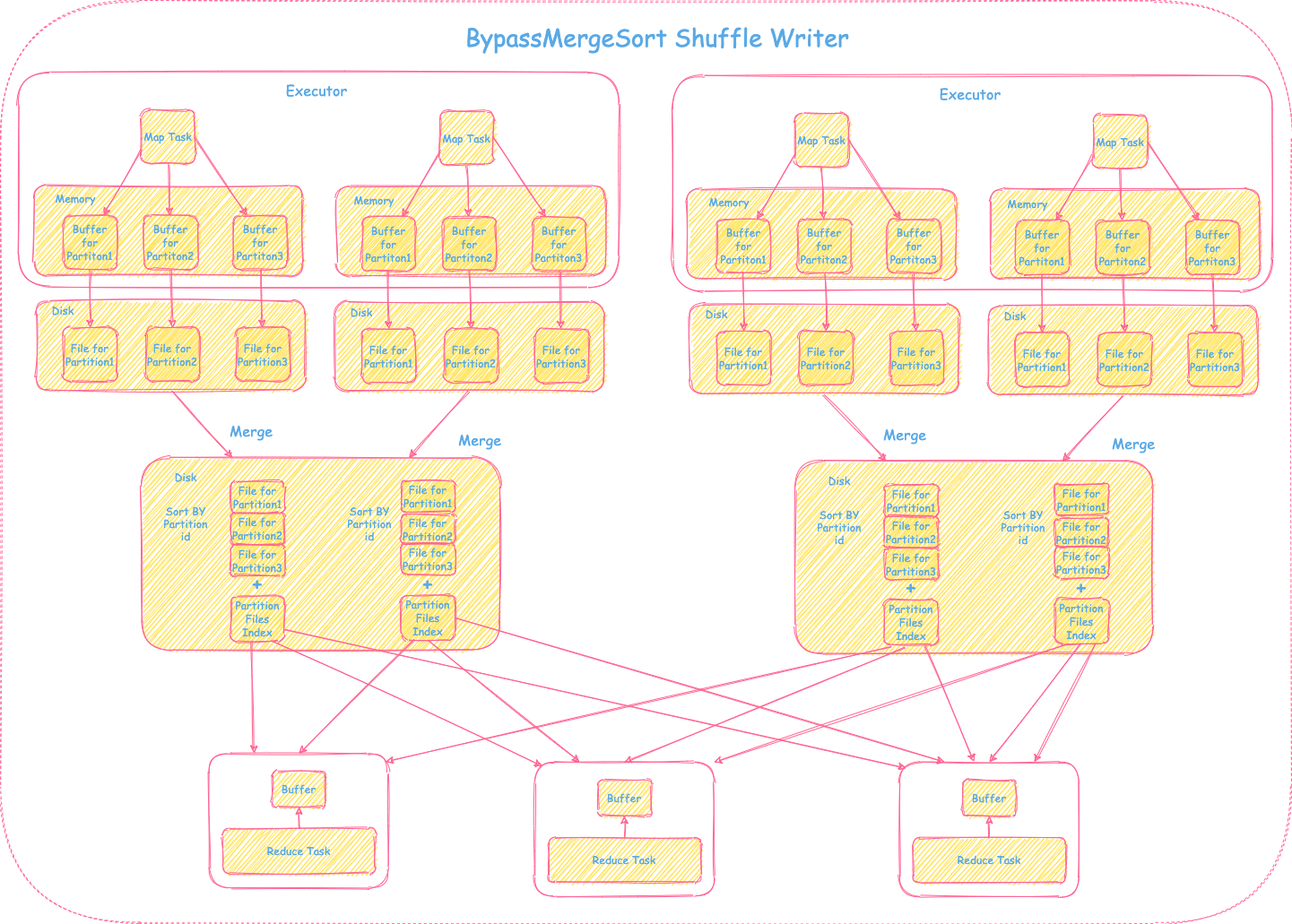
需要注意的是BypassMergeSortShuffleWriter不适合分区比较大的场景,因为在Shuffle Writer阶段,一个map task会为每个分区开一个对应的buffer,如果分区过大,那么占用的内存比较大,性能也会有影响。具体可以参照Spark Shuffle Writer 框架里仅需要map,不需要combine和sort的场景的解释,这里不再赘述。
5) Spark 1.4 引入UnsafeShuffleWriter
UnsafeShuffleWriter是一种Serialized Shuffle,主要是对于map里不需要聚合和排序但是partition个数较多的情况下一种优化。在Shuffle Writer框架里需要map需要sort的场景中提到对于这种场景,用的是数组结构,存放的是普通的record的Java对象。当record比较大时,非常占用内存,也会导致GC频繁。Serialized Shuffle将record序列化以后放在内存,进一步减少内存的占用、降低GC频率。具体可参考下图和前篇关于Shuffle优化部分Serialized Shuffle的介绍:
6) 今天的Spark Shuffle
在Spark 2.0里,第一版的HashShuffleWriter彻底退出历史舞台。今天的Spark Shuffle Writer只有三种writer方式:
- Sort
- SortShuffleWriter(Default)
- UnsafeShuffleWriter
- 也叫tungsten-sort
- BypassMergeSortShuffleWriter
是否需要Sort?
默认模式下用的是SortShuffleWriter的方式,但用户也可以通过指定的方式来选择更适合的Shuffle方式。
- 如果分区个数不超过BypassMergeSort的阈值
spark.shuffle.sort.bypassMergeThreshold,就用BypassMergeSortShuffleWriter。 - 否则就用Sort的方式。
样例代码参见: https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/shuffle/sort/SortShuffleManager.scala
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
用哪种Sort方式?
可以通过spark.shuffle.manager来设置SortShuffleManager,默认是用的普通的sort方式。如果需要用序列化的sort方式进行优化的话,可以将该参数设置成tungsten-sort即可。
1
2
3
4
5
6
7
8
9
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get(config.SHUFFLE_MANAGER)
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
本网站的文章除非特别声明,全部都是原创。
原创文章版权归数据元素(DataElement)所有,未经许可不得转载!
了解更多大数据相关分享,可关注微信公众号”数据元素“
