在上一篇文章里的Spark Shuffle 内部机制(一)中我们介绍了Spark Shuffle Write的框架设计,在本篇中我们继续总结一下Spark Shuffle Read的框架设计。
Spark Shuffle Read框架
Spark Shuffle Read阶段主要解决的是从上游Map产生的数据里拉取对应分区的数据,然后进行重新组织和计算,为后续的操作transformation提供输入数据。主要包括拉取分区数据 --> Aggregate Func(可选) --> Sort(可选)三步计算顺序。
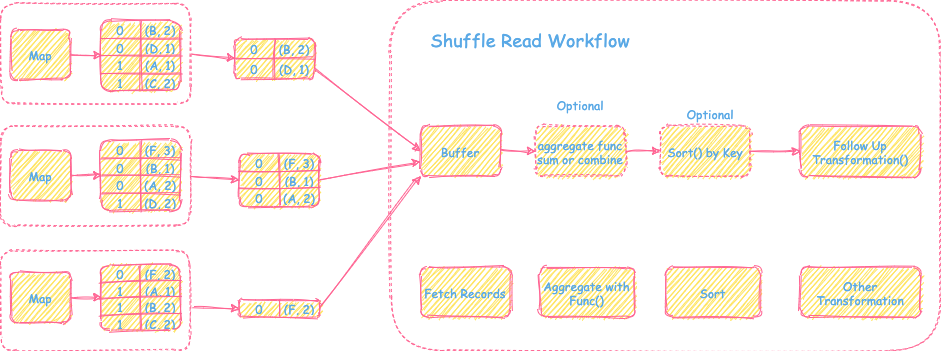
如上图所示,是一个Spark Shuffle Read比较通用的框架流程。接下来会为不同的数据场景需求来分析Spark Shuffle Read阶段具体的实现方式和细节。
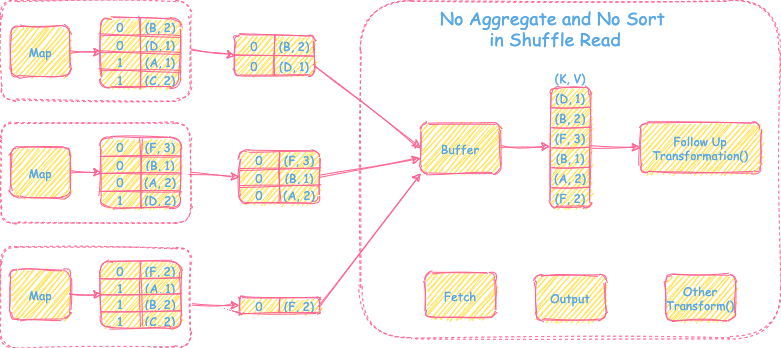
1) 不需要聚合操作,也不需要sort操作
 过程
过程
- 直接从上游Map端拉取reduce task对应的分区文件到buffer里,输出为<K, V>的record然后直接继续后续的transformation操作。
优点
- 内存消耗小,实现简单。
缺点
- 不支持聚合和排序操作。
适用场景
- reduce端不需要聚合和排序的场景,比如简单的partitionBy()操作。
内存消耗
- 拉取数据的buffer空间
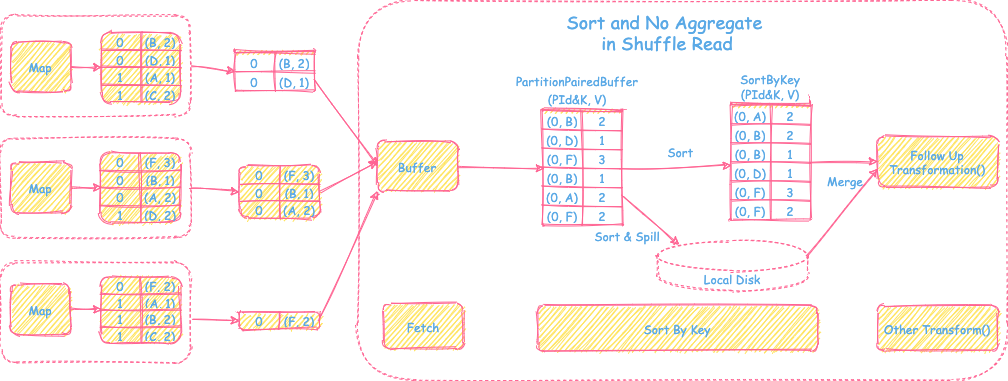
2) 只需要sort操作,不需要聚合操作
 过程
过程
- 直接从上游Map端拉取reduce task对应的分区文件放到内存特殊数组
PartitionPairedBuffer里(具体数据结构会在下文介绍),当数组里的数据装满后会按照partitionId + record key进行排序,spill到磁盘。然后清空数组继续装拉取过来的数据。当所有从map端拉取的数据都处理完后,会将内存里的数据和spill到磁盘里的数据进行全局归并排序,最后交给后面进行其他的transformation操作。
优点
- 支持reduce端的sort操作
- 支持内存+磁盘的方式排序,解决内存不足问题,可以处理大数据量
缺点
- 不支持reduce端聚合操作
- 排序增加时延
适用场景
- reduce端只需要排序不需要聚合的场景,比如sortByKey()
数据结构PartitionPairedBuffer
- 实现
- 底层是特殊array。
- 一条record会占用array里两个相临空间,第一元素是
partitionId+record key,第二元素是recordvalue - 扩容时将底层数组再扩大一倍,然后对数组里的数据copy到新的空间里。
- 局部排序直接将数组里的数据然后按照对应的partitionId或者partitionId+key进行线性数组排序。
- 全局排序再将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局归并排序合并操作即可。
- 优点
- 支持内存+磁盘的方式,可以支持按partitionId 或者 partitionId + record key的方式进行排序。
内存消耗
- 存放数组的sort所需要的数组 + 排序所占用的空间
- 取决于输入数据量的大小
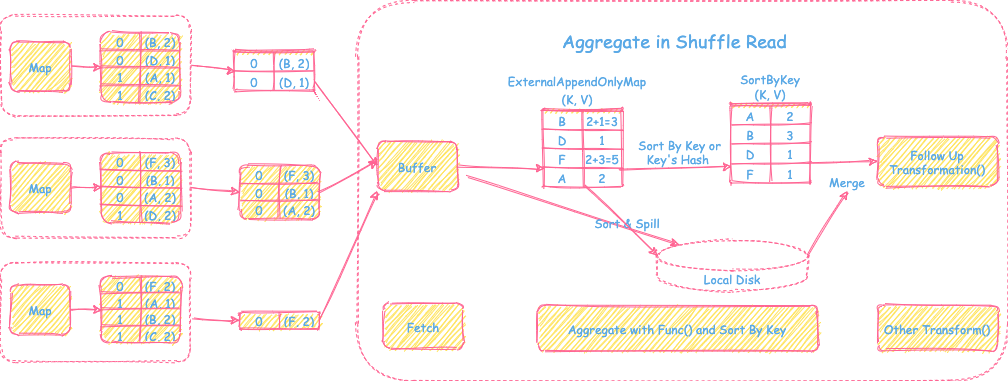
3) 需要聚合操作,需要sort或者不需要sort的操作
 过程
过程
- 从上游map端拉取的reduce tasks对应的分区文件的数据到buffer后,会建立一个HashMap的数据结构
ExternalAppendOnlyMap对buffer的record进行在线聚合。如果HashMap数据放不下后,会先进行扩容,如果内存还放不下。会先按照record的key或者hash值进行排序,然后spill到本地磁盘里。最终map端的数据处理结果以后,会将磁盘里spill的文件和内存中排好序的数据进行全局的归并聚合,再交给后面的其他的transformation操作。
优点
- 支持reduce端的聚合和sort操作
- 支持内存+磁盘的方式在线聚合和排序,解决内存不足和等所有map的数据都拉取结束再开始聚合的时延问题,可以处理大数据量
缺点
- 聚合排序增加内存消耗和时延
适用场景
- reduce端需要聚合的场景,比如reduceByKey(), aggregateByKey()
数据结构ExternalAppendOnlyMap
同上一篇文章里的Spark Shuffle 内部机制(一)中PartitionedAppendOnlyMap数据结构,是一个类似的HashMap结构,只不过PartitionedAppendOnlyMap的key是partitionId + record key, 而ExternalAppendOnlyMap的key是record key。
- 实现
HashMap + Array的结合体。- 仅支持对数据的增加和更改操作(Append Only),不支持删除操作。
- 底层是一个线性数组,通过对key(record key)的hash,然后按照hash值在数组中通过探测的方式找到存放和读取的位置
- 如果hash值对应的位置没有存放数据,那么就把对应的数据放进去。
- 否则,看临近的下一个位置是否是空的,依次探测,直到找到一个空的位置放进去即可。
- 读取的时候也是类似的根据hash值探测方式读取,然后将值combine以后再update回去。
- 扩容时将底层数组再扩大一倍,然后对数组里的数据再rehash重新放置。
- 局部排序: 将数组的数据都移到最前方的位置,然后按照对应的key的hash值或者key(需要按照key排序的场景)进行线性数组排序。
- 如果按照key的hash值排序,当hash值相等时,会进一步看key是否相等,来判断是否是hash冲突引发的相等。
- 全局排序: 在将spill的数据和内存里的数据进行全局排序和merge时,通过建立最小堆或者最大堆进行全局排序合并操作即可。
- 优点
- 不需要额外占用内存空间来进行HashMap结构到线性结构的copy转化过程。
内存消耗
- 在线聚合需要的HashMap数据结构 + 中间聚合过程用户代码所占用的数据空间 + 排序所占用的空间
- 取决于分区输入数据量的大小和用户聚合函数的复杂性
到这里,我们基本上对Spark Shuffle的Write和Read两部分的设计有了一个总体的了解。下一篇文章里,会再进一步总结Spark Shuffle的前世今世,敬请关注。
Reference
Spark 官方文档
《大数据处理框架Spark的设计与实现》
Hadoop之MapReduce内部机制
Spark Shuffle 内部机制(一)
本网站的文章除非特别声明,全部都是原创。
原创文章版权归数据元素(DataElement)所有,未经许可不得转载!
了解更多大数据相关分享,可关注微信公众号”数据元素“
